Counting Bondi Salties swimmers with a little help from AI

This is a story about a new way of building software: in dialogue with an LLM. In this case, Claude 3.5 Sonnet from Anthropic.
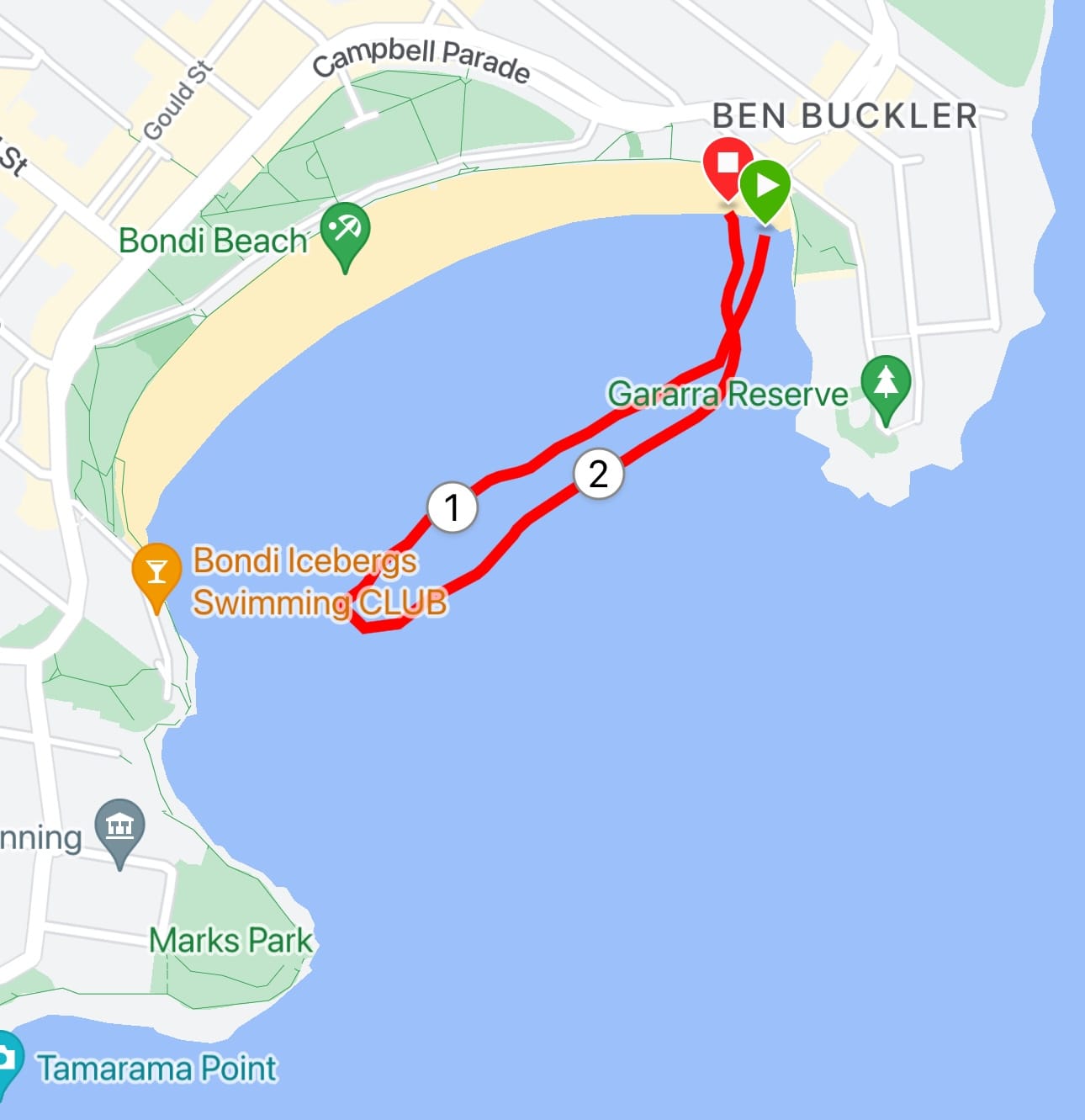
I'm a software engineer who loves to swim. It began with curiosity. Look at that photo up top: how many people are there?
Living in Bondi Beach you learn the joy of ocean swimming. Our community, Bondi Salties, loves to get salty each Friday with a big group swim! When we get in the water it's quite a sight (credit @bondiripper):

According to my GPS watch we swim about 1.4km:
After swimming everyone bunches up for a quick photo on the beach before it's time to change and catch up over coffee.

You can have a look via drone (credit @bondiripper). Swimming at sunrise in a huge crowd is profound in a way that's hard to explain. Seeing that photo each week begs the question: how big was the group?
The question has been bouncing around for years - especially as the group grows every summer. We could count by hand, but this seems like something a computer should handle. Sadly while I know a little about building software, I wouldn't know where to start when it comes to recognizing faces in images.
Luckily two recent developments change the game:
- Image recognition became much easier
- LLMs - in particular, the ones accessible on paid subscriptions - now produce software in seconds that would have taken hours to research, write, and debug.
It's become possible in my limited spare time to build the app of my Salty dreams. The app to end all apps. An app to count the swimmers and spit out a number and put everyone out of their hand-counting misery.
A wrong approach: trying to detect humans using Segment Anything
I fired up Claude and enabled Artifacts. The plan was to use Segment Anything, as SAM 2 had recently been released and I was excited to try it out. SAM 2 is for video, but its predecessor, Segment Anything, was several years old at this point and is well known as a tool for pulling objects out of images, just like I wanted to do.
Me: I need a web app that can accept an image to upload and use Segment Anything to count the number of humans in the image.
Claude: I understand you're looking to create a web application that can accept image uploads and use the Segment Anything model to count the number of humans in the image. This is an interesting project that combines web development, image processing, and machine learning. Let's break down the components we'll need and create a basic structure for this application.
(...)
Claude generated a Flask application in python, which used Segment Anything, as instructed. The app was a single file (chat transcript)
Claude: This Python script sets up a Flask web application that can accept image uploads, process them using the Segment Anything Model (SAM), and count the number of humans in the image. Here's a breakdown of the main components:
(...)
Skipping the output as this post is about the process. The transcript is linked above if you are curious! Claude explained what it had done and how to finish the application: we would need to install the code libraries that it used as dependencies, and also create a HTML template to send output to a web browser a the user could upload images to be processed.
Claude: Would you like me to provide the HTML template for the upload form? Or do you need any clarification on the Python code?
Choosing an approach and getting you started is where AIs like Claude shine: they have the "world knowledge" to give you that starting point, avoiding, for want of a better term, the "blank page problem".
Claude chose to create a single-file Flask app in python. It set up a handler for the upload which created a SamPredictor, converted the uploaded image to a numpy array and fed it in, all of which I'd have had to research. This might be where I would've given up.
But there is a wrinkle. Claude's planned approach was a hallucination. It counted any object having mask.sum() > 1000, which I suspect is a sum of every coordinate in the mask. That isn't distinguishing a person from a seagull from a grain of sand from the sky. After some research - face palm - I learned that Segment Anything doesn't have the ability to classify objects. Mea culpa, oops, I had sent the AI down a bad path and set it up for failure.
Admitting I knew less than I thought and letting Claude choose
Just let Claude decide.
Me: What techniques and/or models can be used to ensure only humans are counted? maybe Segment Anything wasn't the best tool for the job
Claude: You're right to question whether Segment Anything (SAM) is the best tool for this specific task. While SAM is powerful for general segmentation, it doesn't specialize in human detection. For counting humans in images, there are indeed more suitable techniques and models. Let's explore some better options:
(...)
Given this information, let's modify our web app to use YOLOv5, which is a good balance of speed and accuracy for human detection. We'll use the PyTorch implementation of YOLOv5.
Claude rewrote the app with this new library for me and told me what it was doing and how it worked. And it pointed out that I was yet to ask for the HTML template file the app was using to send HTML output to the browser.
Me: What's in index.html?Claude generated a nice HTML template and explained its contents. It suggested adding a loading indicator which seemed like a great idea! (chat transcript)
Me: Can you add the loading indicator?
Claude: Certainly! I'll add a loading indicator to the HTML template. This will provide visual feedback to the user while the image is being processed.
(...)
At this point I was ready to run the app locally, barring a full set of dependencies. In python you generally put these in a file called requirements.txt, so I knew Claude would know what I was talking about when I asked:
Me: Can you generate a requirements.txtThe requirements.txt had a laundry list of web frameworks and machine learning libraries: flask, torch, torchvision, opencv-python, and numpy. Seemed all good!
Running the app - and getting it to actually work
Me: how do I launch it
Claude generated helpful launch instructions which jogged my memory of how to run a basic Flask app. Time to put the code in a directory and get the app running!
$ cd ~/src
$ mkdir HowManySwimmers
$ cd HowManySwimmers
# Copy in the files generated by Claude Artifacts:
# app.py, index.html, requirements.txt
python3 -m venv venv # I needed to use python3 on my Mac, not python
. ./venv/bin/activate
pip install -r requirements.txt
# ... wait for installation
flask runAt the first run of the app I faced several problems, nothing impossible but still a lot:
- The pinned dependency versions in
requirements.txtcaused errors withpip install. Claude's training cutoff means it doesn't know the latest versions to use. So I unpinned them which should givepipfreedom to install whatever combination is best. - Not all dependencies were in Claude's generated
requirements.txt, requiring lots of Googling to fix and lots of things added to the list. In particularModuleNotFoundError: No module named 'pandas'andModuleNotFoundError: No module named 'numpy.strings'errors both required extra steps to get things installed properly, though pasting the errors verbatim to Claude gave me what I needed to fix them. - The app was unresponsive after launch. Everything seemed OK and after a lot o back and forth I discovered the default Flask port of 5000 is in use on recent Macs. You must invoke Flask apps with
flask run --port=8080, or any port of your choice, other than 5000. - I was getting "template not found" error from
render_template. Turns outindex.htmlcannot be at the repository root and needs to be attemplates/index.html. Claude did not know how to fix this problem!
With all these solved, the app started up! I eagerly loaded an image and clicked the very pleasantly named "Count Humans" button. Et voila, a count! But wait - a count of what??? There's no image!
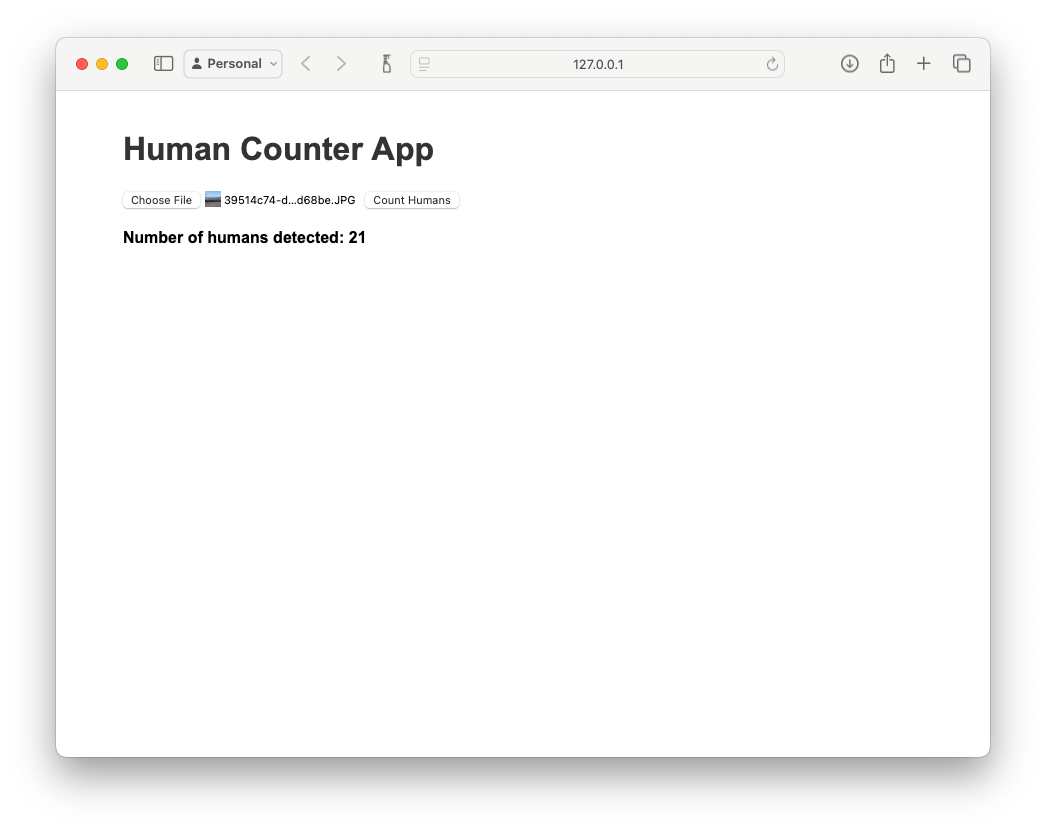
It really should show the detected objects and their bounding boxes...
Me: Make it show the bounding boxes of the counted humans
Claude blew me away, it added code to draw green boxes around each detected region. Researching how to do this would have taken me hours!
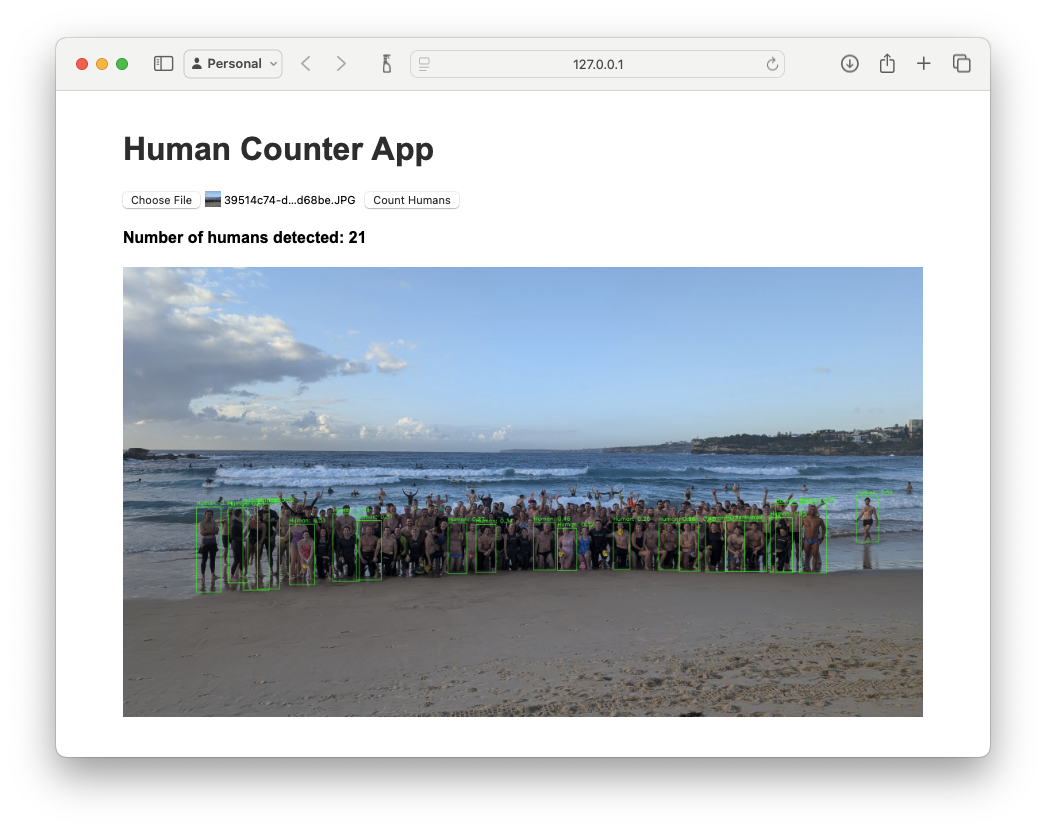
Body detection was missing at least half the people in the photo. It did even worse on blurry photos and low-res photos where people were only a few pixels. What about swapping to face recognition, my original plan?
Me: What about just making it detect faces.
Claude: Certainly! Detecting faces instead of full bodies is a more focused task and can be more efficient. We'll use the popular face detection library calledface_recognitionfor this purpose. It's based on dlib and provides good accuracy for face detection.
(...)
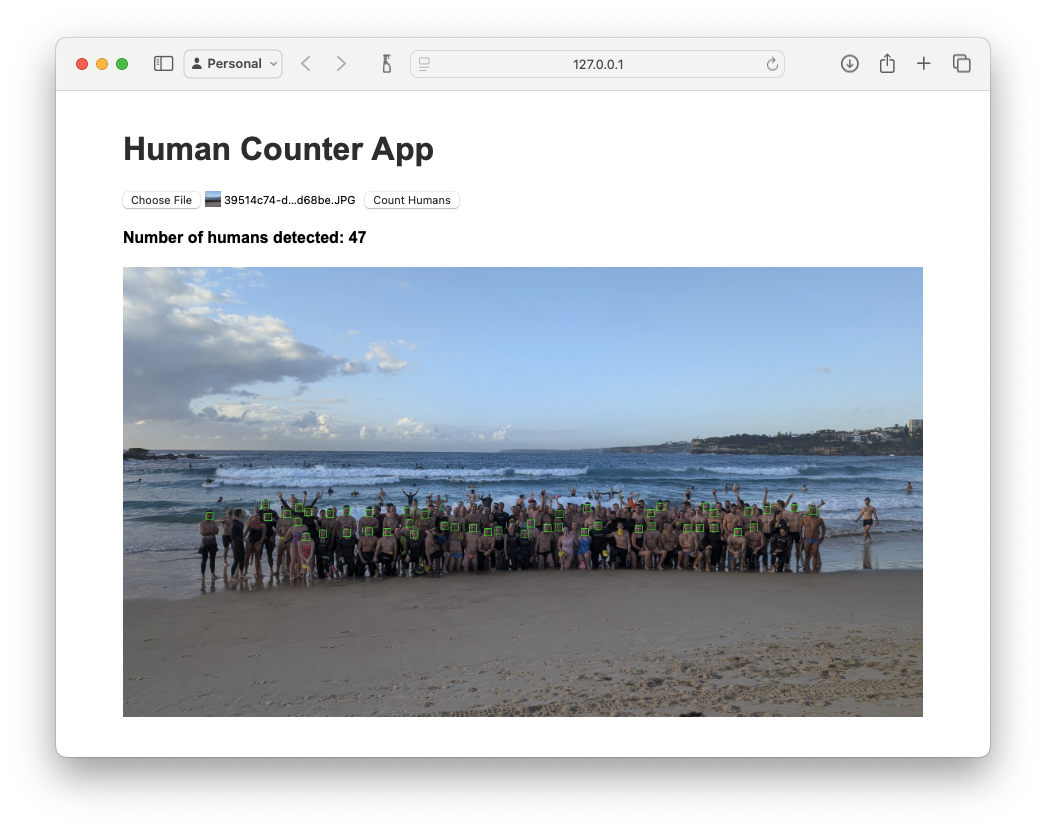
Fantastic! We increased from 21 to 47. Starting to catch a decent amount of the people in the photo! But can we trust it? How many bounding boxes are there?
Me: Can it add a little number at the corner of each bounding box?
Claude did it - even making the numbers white for visibility against various backgrounds.
Me: Let the output image be at full size, not bound to the width of the container
This didn't work, but after a bit of poking around in DevTools I discovered the magical incantation was to remove overflow-x from the image's container div. With the image at full size the numbers on the faces became readable.

Oh look, the numbers are out of order. Easy fix!
Me: Make the little numbers be from lowest number at the left to highest number at the right
Claude: Certainly! We can modify the face detection process to number the faces from left to right. To do this, we'll need to sort the face locations based on their x-coordinate before numbering them. Let's update ourapp.pyfile to implement this change.
(...)
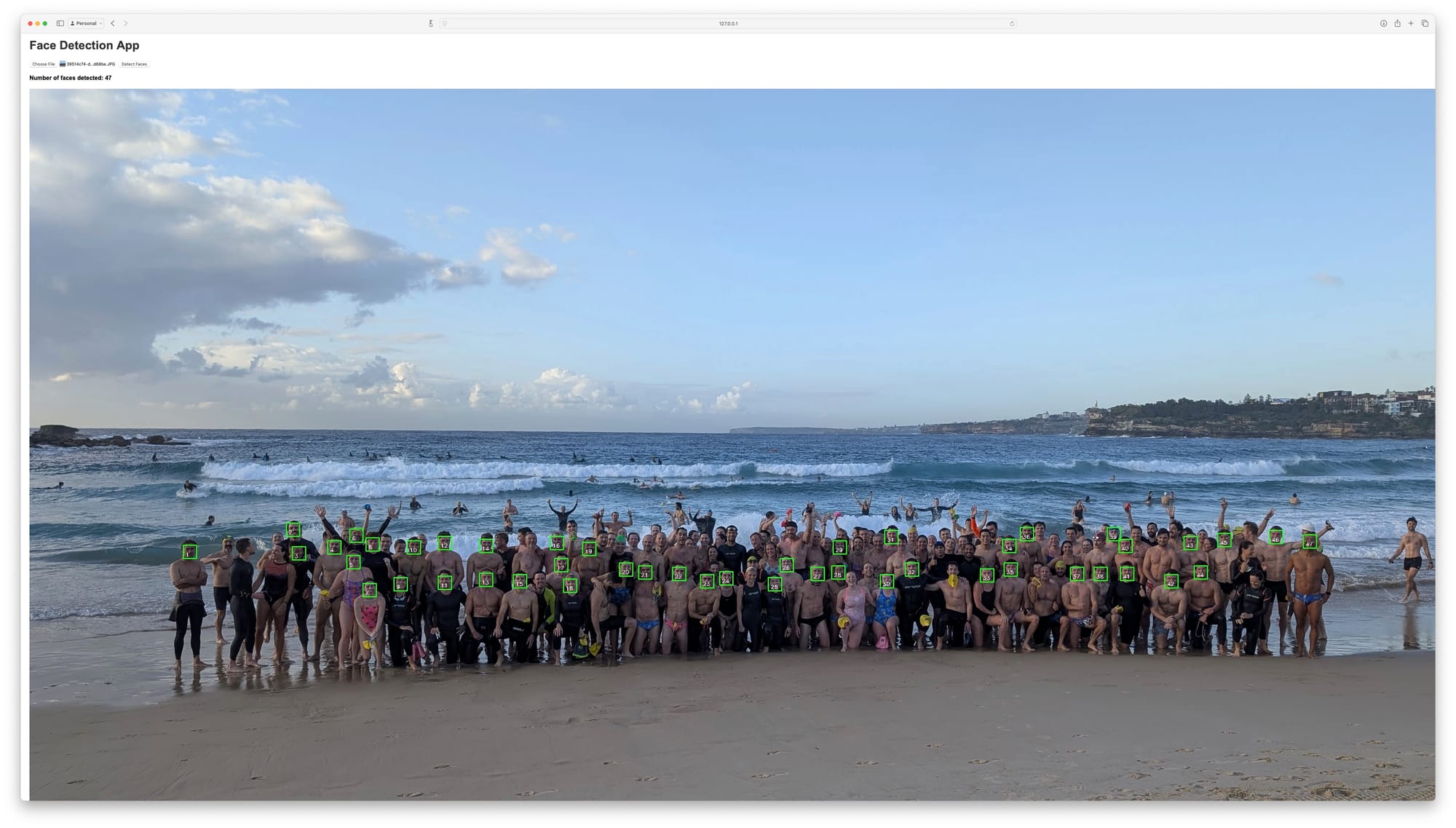
Not all the faces were detected but a manual count could close the gap. At this point I had something ready to demo! I did some edits to the top text, made some changes to the website, committed the code to a GitHub repo, and posted to our group chat, where it was well received:
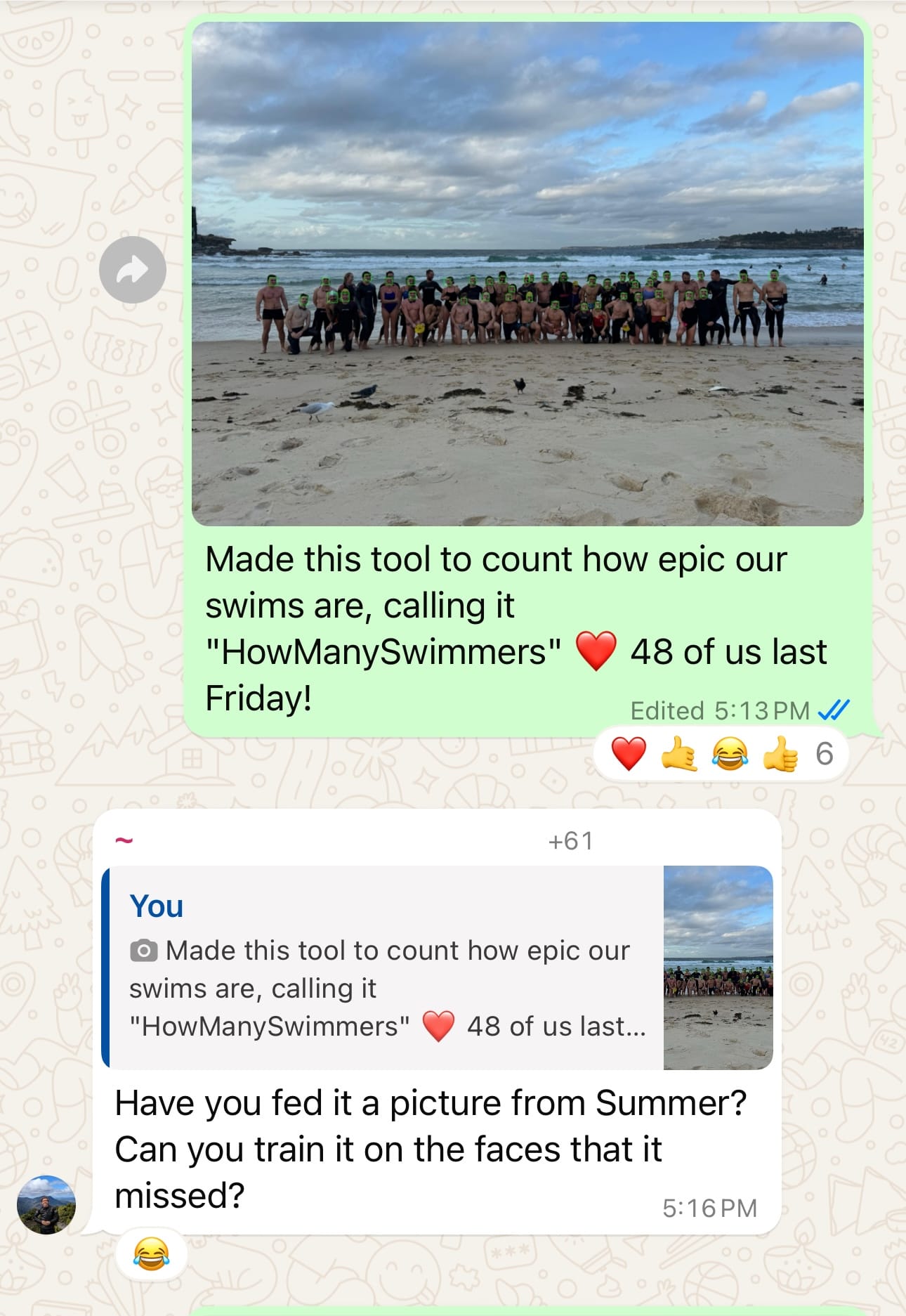
(The group chat post used a photo from a swim last month.)
Continuing to increase the accuracy
I had a process: upload an image, then run a careful eye over it, decreasing the count by one for each false positive and adding one for each face missed. People turning to the side or partially blocked are missed by the algorithm but not by Chris! Gotta have an accurate count!
Still, it was more work than I wanted to do. Software engineers are a weird kind of lazy: we will do unreasonable amounts of work to automate a tedious task that would take way less time the slow way!
What about upscaling the image before running the face recognition:
Me: I have this flask app which accepts an image and does face recognition.
(...)
Can you make it upscale the uploaded image so the face recognition works better?
Claude had the app upscale after upload using cv2.resize(). (chat transcript) but simple upscaling didn't do too much for accuracy, so maybe Claude knows about a "smart" way of sharpening the upscaled image?
Me: What about using a neural net to upscale?
Claude mentioned that this approach is well known (chat transcript), it's called super-resolution and OpenCV has a module called DNN Super Resolution which could be used with the ESPCN model (mentioned in the above article)... since I was more interested in testing the next iteration, and Claude had impressed me so far with its ability to recommend and implement these approaches, I just took the code and ran a test.
Me: I get AttributeError: module 'cv2' has no attribute 'dnn_superres'Claude suggested uninstaling opencv-python and replacing it with opencv-contrib-python. I'm not sure how long this would've taken to fix on my own. I'm grateful Claude's fix worked.
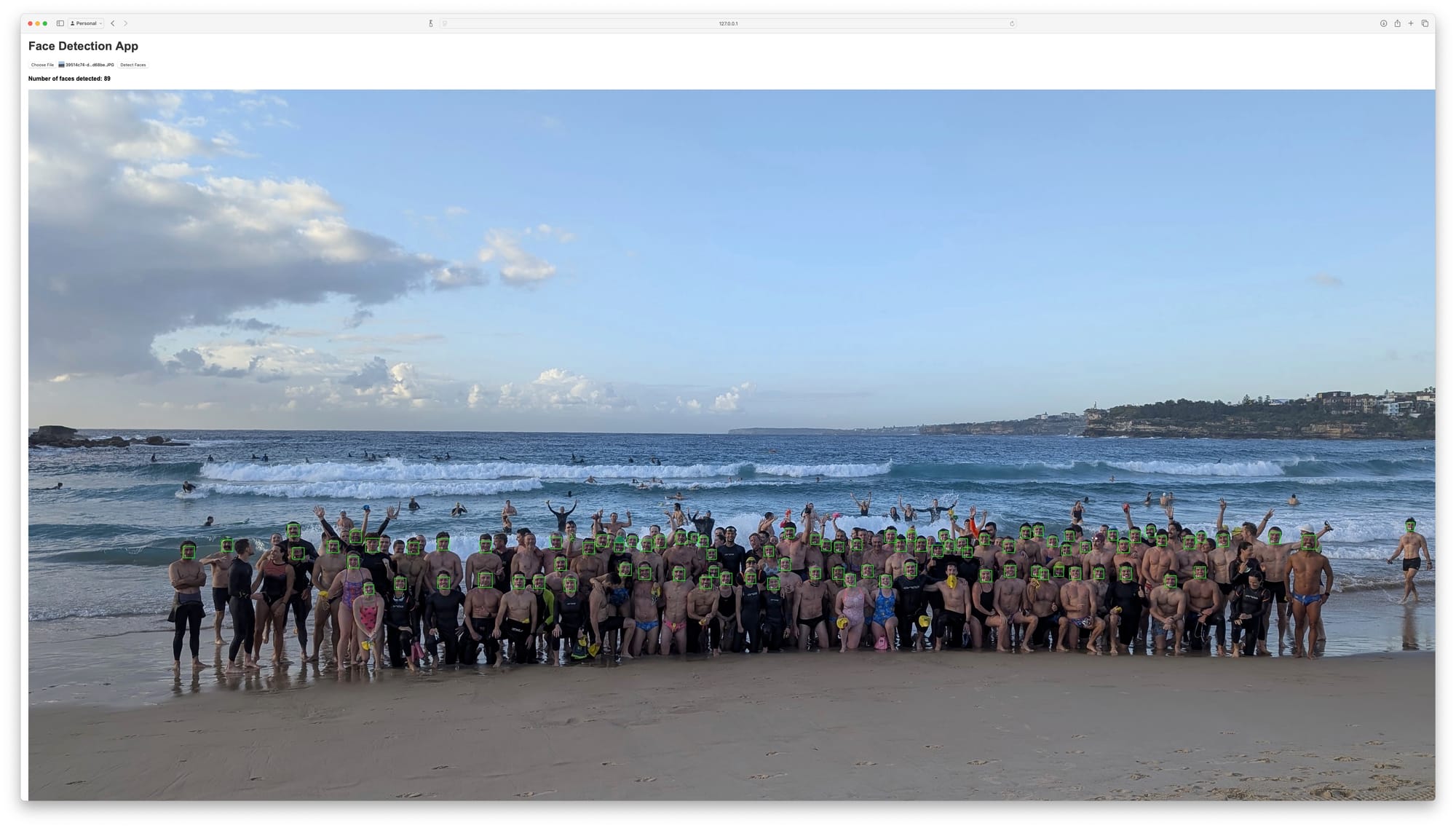
Accuracy improved enough to only be adjusting the count by a few dozen before giving the count to the group chat!
We've gone from counting 21 bodies with YOLOv5 to 47 faces with face_recognition to 89 with super-resolution. We've added bounding boxes and numbers so I can prove the result is trustworthy. There are still lots of faces to count each time but still I am stoked with this result!
Another change of approach: MTCNN
At coffee the following Friday a fellow swimmer suggested trying MTCNN. It had me curious... (chat transcript)
Me: Can you make it do the face detection with MTCNN?
Claude replaced the face_recognition library with MTCNN, initializing the detector at startup and using it in the exact way it needed to be used. It kept the bounding box and left-to-right ordering of numbers which left me seriously impressed!
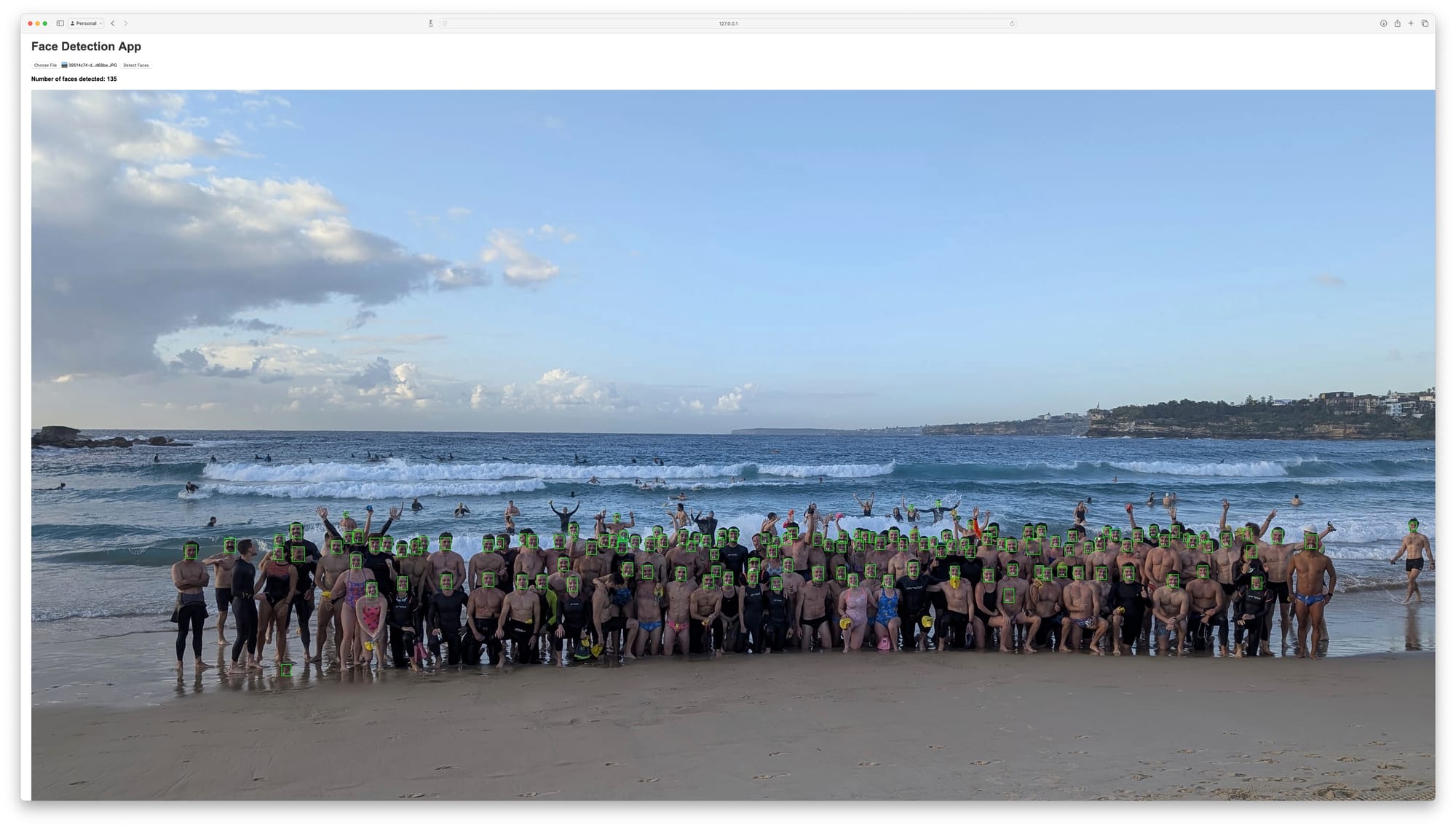
MTCNN takes a lot longer, but is drastically better. Only a few faces are ever missed and counting is a breeze. It does catch the odd knee here and there but that's easy to account for.
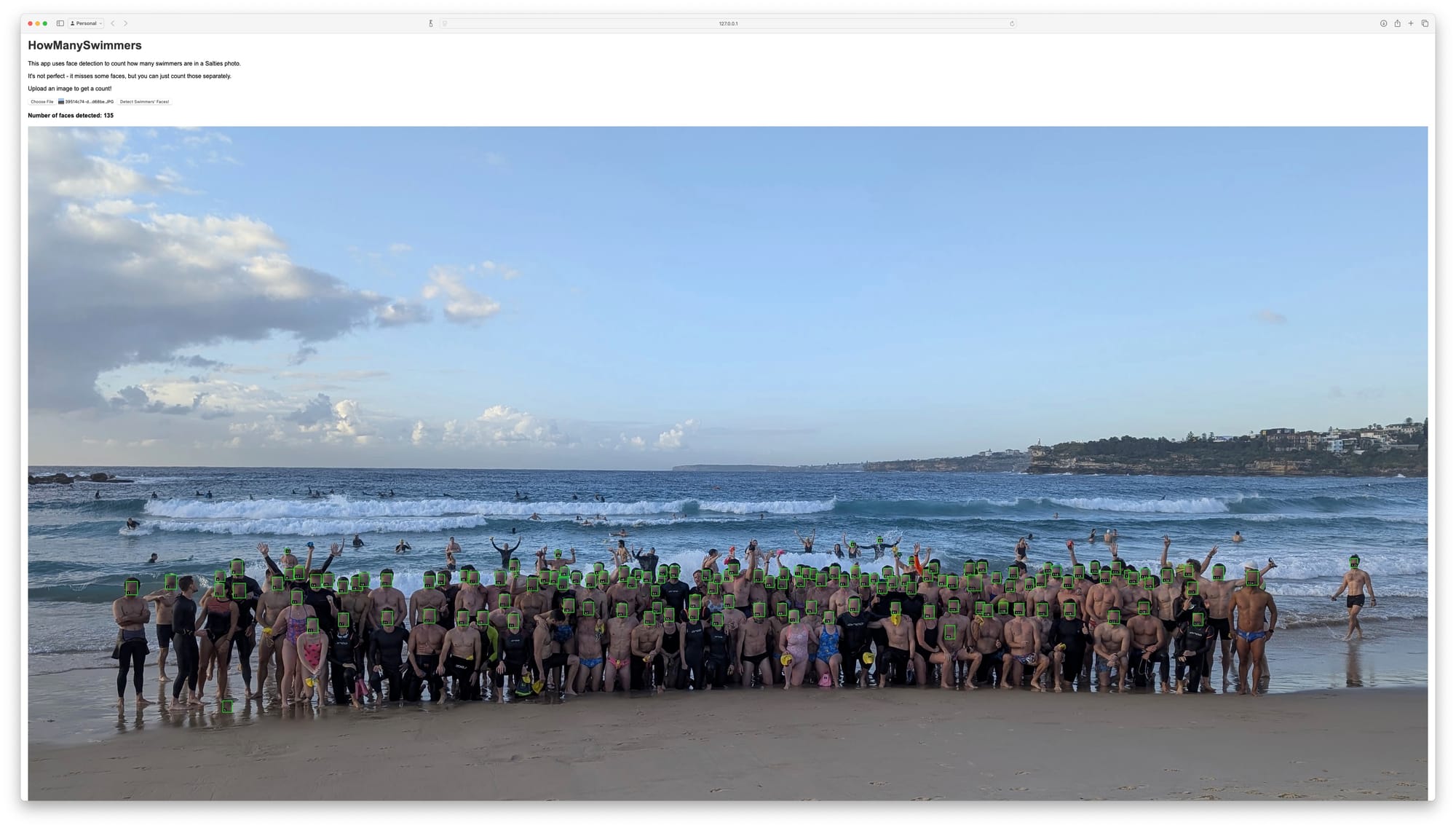
From 21 to 47 to 89, and now the app recognizes 135 faces, almost all of them - even those turned to the side. This was finally it!
One last thing.. blurring faces
Posting people's faces online seems like a bad idea. This one was handled deftly and easily by Claude (chat transcript)
Me: I have this Flask app, can the insides of the boxes please be blurred so the faces aren't recognizable?
(...)
Done. (chat transcript) After a couple more iterations and some more editing of the HTML template we have a simply fantastic result - solid recognition, numbered bounding boxes, and blurred faces.
Future directions
I'm proud of how this turned out. The app's source is on Github for anyone to modify. Hats off to Anthropic's team for a great product.
The app could be deployed somewhere like Vercel, but upscaling and processing images is CPU-intensive. And it's only needed once a week. So for the foreseeable future I plan to keep firing it up locally, getting a count, then killing it until next week. It could be automated but someone still needs to upload the image.
HowManySwimmers would have never been built without AI making it easy enough to happen in my spare time. The world is chock full of software just like this. So many people have ideas they can't realize because they're busy or lack the skills. But now it's possible.
Building in dialogue with AI changes the game. You'll realize your ideas in record time - before you get bored! - and you are way less likely to lose hours to some annoying problem unrelated to what you're building.
Excited to see what folks who would've otherwise lacked the knowledge & time can create with the help of these models.
Credit to Simon Willison for this chat export tool!